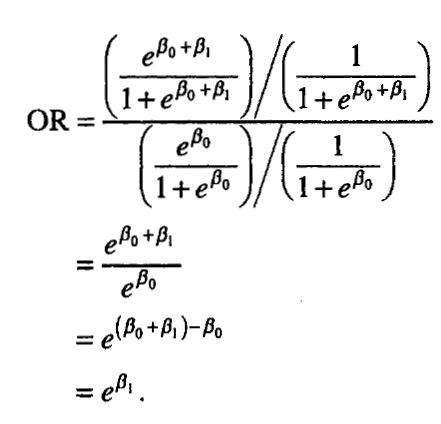In a
previous post I noted Hal Varian and Andrew Gelman's discussion on instrumental variables, and the following specification for program or treatment T and instrument Z :
"You have to assume that the only way that z affects Y is through the treatment, T. So the IV model is
T = az + e 1
y = bT + d
It follows that
E(y|z) = b E(T|z) + E(d|z)
Now if we
1) assume E(d|z) = 0
2) verify that E(T|z) != 0
we can solve for b by division
i.e. b = E(y|z) / E(T|z)
In a recent paper
'Using Instrumental Variables to Account for Selection Effects in Research on First Year Programs' Pike, Hansen and Lin expand on the details following the work of Angrist and Pischke. They describe selection bias for participation in first year programs at 4 year universities in the context of omitted variable bias.
Yi = α + βjXij + pDi + η
where Xij may or may not be related to Di, which is program participation.
p = the unbiased effect of program participation
and η = γSi + v
Given that γSi is related to program participation, it causes the effect of program participation to be overstated.
Pike, Hansen and Lin propose capturing the impact of selection bias using instrumental variables (Z) to ultimately measure the impact of program participation, p.
p = cov(Y, Z)/ cov(D, Z) = Π11 / Π21
Where impact of program participation is derived from the ratio of two regressions, Y on Z and D on Z.
Y = α1 + βX + Π11Z + e1
D = α2 + βX + Π21Z + e2
As they explain in their paper, the ratio for p as it is defined above is useful in thinking about the consequences of the two major assumptions of IV analysis.
1) Z should be strongly correlated with D. If the correlation is week, then the denominator will be small, and p will be overstated.
2) Z should be unrelated to Y and 'e'. If the correlation is strong, then the numerator will be large, and p will overstate program effects.
In the paper, they correct for the impact of selection bias using two instruments (participation in a summer bridge program and having decided a major prior to enrollment). In a normal regression, they find that even after correcting for various other controls, there is a positive significant relationship between first year programs and student success (measured by GPA). However, by including the instruments in the regression (correcting for selection bias) this relationship goes away.
Instrumental variable techniques add a valuable tool that all policy analysts and researchers should have in their quantitative tool box. As stated in the paper:
"If, as the results of this study suggest, traditional evaluation methods can overstate (either positively or negatively) the magnitude of program effects in the face of self selection, then evaluation research may be providing decision makers with inaccurate information. In addition to providing an incomplete accounting for external audiences, inaccurate information about program effectiveness can lead to the misallocation of scarce institutional resources."
References:
Angrist and Pischke, Mostly Harmless Econometrics, 2009
Using Instrumental Variables to Account for Selection Effects in Research on First-Year Programs
Gary R. Pike, Michele J. Hansen and Ching-Hui Lin
Research in Higher Education
Volume 52, Number 2, 194-214, DOI: 10.1007/s11162-010-9188-x